智商测试信效度:专业评估
发布时间:2026.05.25
你是否曾在网络上尝试过各类“智商测试”,却对结果的可靠性存疑?正版智商测试作为专业心理测评手段,究竟如何确保评估的科学性?今天,我们将深入探讨智商测试的核心特征、应用场景及理性看待的方式。
过去十年中,在线IQ测试的流行度急剧上升。随便一搜就能找到数百个网站,承诺在10到30分钟内揭示你的智商——通常还是免费的。但一个基于浏览器的测验真的能衡量像人类智力这样复杂的东西吗?答案,就像智力本身一样,是复杂的。
要了解在线IQ测试的准确性,我们首先需要了解是什么让任何一种智力测试有效。心理测量学——心理测量科学——为区分有意义的评估与娱乐性测验提供了明确的标准。根据美国心理学会(APA),智力测试必须满足严格的信度、效度和标准化标准,才能产生有意义的结果。

一、什么是智商测试?
智商测试是由专业心理测评机构或心理学家团队开发,遵循严格标准化程序的认知能力评估工具。它以经典智力理论(如卡特尔流体-晶体智力理论、韦氏智力框架)为基础,通过系统题目设计、施测流程和评分标准,评估个体在言语理解、逻辑推理、空间认知、记忆力、信息处理速度等核心维度的表现。与非正版测试(如网络趣味测试)相比,其核心特征在于具备可靠的信度(结果稳定性)、效度(评估准确性)和代表性常模(同类人群比较基准),开发修订需经过严谨科研验证。
二、智商测试的核心内容与应用场景
正版智商测试通常覆盖多个认知维度,如韦氏智力测验包含言语理解、知觉推理、工作记忆、处理速度四大模块;斯坦福-比奈测验涵盖流体推理、知识、数量推理等五个领域。形式上分为纸质或计算机化版本,部分需专业人员一对一施测(如儿童智力量表),部分可通过标准化程序完成(如成人认知评估)。应用场景包括:教育领域(特殊教育需求初步筛查参考)、职业咨询(特定岗位选拔辅助)、科研领域(认知发展研究数据收集)等,但需明确,它不能替代临床诊断或作为能力判断唯一依据。
三、智商测试的评分标准与参考范围
智商测试评分基于常模数据转换,通用标准与参考范围(标准差通常为15)如下:
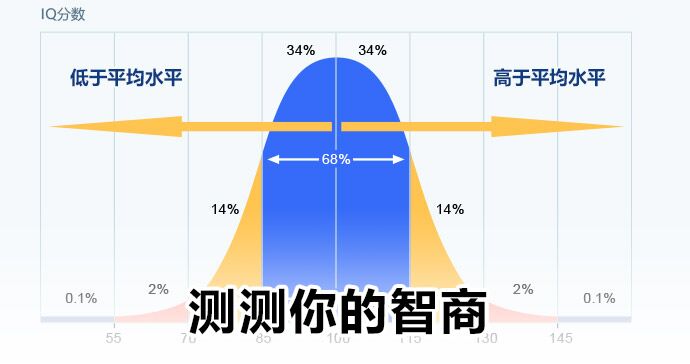
常模基础:大规模年龄分层代表性人群样本,确保分数可比性;IQ分数计算:原始得分转换为标准分,平均值100,标准差15。
分数区间参考:130及以上为极优秀(约占人群2.2%);120-129为优秀(约占人群6.7%);110-119为中上水平(约占人群16.1%);90-109为中等水平(约占人群50%);80-89为中下水平(约占人群16.1%);70-79为临界水平(约占人群6.7%);69及以下为极低水平(约占人群2.2%)。
注意事项:分数受测试状态、环境影响,需专业人员结合背景综合解读。
四、智商测试的优缺点分析
优点:标准化程度高,施测、评分规则严格,减少主观误差;信效度可靠,经科研验证,确保结果稳定与评估准确;常模时效性,定期修订常模,适应社会发展对认知的影响;多维度评估,覆盖核心认知维度,提供全面表现参考。
缺点:成本与门槛高,专业测试需付费,部分需持证人员施测,普及性受限;耗时较长,经典测试如韦氏需1-2小时完成,对耐心要求高;维度局限,难以涵盖创造力、实践智力、情绪智力等非传统维度;结果易受干扰,测试时情绪、环境等因素可能影响分数真实性。
五、权威智商测试的核心评判标准
并非所有名为“智商测试”的工具都具有同等价值。最权威的智商测试必须满足严格的科学标准,这些标准构成了评估工具专业性的基石。
科学信度与效度验证。权威测试必须经过大规模样本检验,证明其测量结果稳定可靠(信度)且确实测量了智力而非其他因素(效度)。例如,韦氏系列测试的再测信度系数通常高达0.90以上,这意味着同一人短期内重复测试的结果高度一致。
标准化常模体系。真正的权威测试需要建立代表性常模数据库。2026年最新标准要求常模样本不少于2000人,且必须覆盖不同年龄、性别、地域和教育背景的群体。这样的常模才能为个体分数提供有意义的比较基准。
专业施测与解读要求。最严谨的智商测试必须由受过专业培训的心理学家或认证施测员操作。测试环境、指导语、时间控制和结果解释都有严格规范,这是区分专业评估与娱乐性自测的关键分水岭。
六、2026年国际公认的主流权威智商测试
根据国际心理科学联合会(IUPsyS)2026年发布的最新指南,以下测评工具在全球范围内获得最高专业认可:
韦氏成人智力量表第四版(WAIS-IV)。被誉为智商测试领域的“黄金标准”,WAIS-IV包含10个核心分测验和5个补充分测验,全面评估言语理解、知觉推理、工作记忆和加工速度四大认知领域。其2026年数字化版本已整合AI辅助分析功能,但施测仍须由注册临床心理学家监督。
斯坦福-比奈智力量表第五版(SB5)。作为历史最悠久的智力测验的现代版本,SB5采用适应性测试模式,根据被试表现动态调整题目难度。其独特优势在于覆盖2岁至85岁的超宽年龄范围,且流体推理与晶体知识分离计分,更符合当代认知理论。
瑞文标准推理测验(SPM-Plus)。对于需要文化公平评估的场景,2026年更新的SPM-Plus版本是最权威的智商测试选择之一。完全非语言的图形推理设计使其跨文化偏差最小化,在国际人才选拔和多元背景评估中优势显著。
考夫曼儿童评估成套测验第二版(KABC-II)。专为3-18岁儿童设计,KABC-II的最大特色是区分学习与成就,避免将教育机会差异误判为智力水平。2026年新版增加了执行功能模块,更贴合当前儿童发展心理学研究前沿。
七、警惕误区:这些不是权威测试
在追求最权威的智商测试时,务必识别常见陷阱:免费在线自测,多数缺乏信效度数据,题目未经标准化,结果仅供娱乐;单一维度测试,仅测量逻辑推理或空间能力的工具不能代表整体智力;过度商业化产品,宣传“30分钟快速测IQ”或“99%准确率”的基本不符合科学标准;缺乏常模更新的老版本,使用10年以上未修订的测试可能产生“弗林效应”偏差。
八、正确理解智商分数的意义
即使通过最权威的智商测试获得分数,专业解读也至关重要。智商分数并非固定不变的标签,而是特定时间点的认知能力快照。标准差为15的正态分布意味着:100分是人群平均值,115分以上约占16%,130分以上仅约2%。更重要的是分析分测验剖面图,识别个体的认知优势与弱势领域,而非纠结于单一总分。
此外,智商测试不测量创造力、毅力、道德品质或实践智慧。2026年心理学界共识是:智力是多维度的,任何单一测试都只能反映部分真相。
九、什么使IQ测试有效?
信度。信度是指测试结果的一致性。如果你在相似条件下两次参加同一测试,应该得到相近的分数。心理测量学家使用几种方法来衡量信度:重测信度,在不同时间向同一批人施测并比较结果,像韦克斯勒成人智力量表(WAIS)这样经过临床验证的测试,重测相关系数达到0.90或更高,被认为是优秀的;内部一致性,衡量测试中理应测量相同能力的不同题目是否产生相关结果;评分者间信度,对于需要主观评分的测试,检查不同主试者是否以相同方式评分。大多数在线IQ测试从未经过正式的信度评估,没有已发布的信度数据,就无法知道你今天得到的分数是否与下周得到的分数相近。
效度。效度考察测试是否真正测量了它声称要测量的内容。效度有几种类型:构念效度,测试是否测量了一般智力(g因子)这一心理构念;效标效度,测试分数是否能预测真实世界的结果,如学业成绩或工作成功;内容效度,测试是否涵盖了适当的认知能力范围。WAIS-IV和斯坦福-比内智力量表(第五版)等成熟的临床测试,有数十年的研究证明其效度。它们测量多个认知领域,包括语言理解、知觉推理、工作记忆和处理速度,其分数与学业成就、工作绩效及其他认知测量有意义地相关。大多数在线测试只专注于模式识别或矩阵推理——这只是智力的一个切面。虽然这些能力确实是智力的一部分,但它们无法呈现全面临床评估所提供的完整图景。
标准化。标准化或许是在线测试和临床测试差异最显著的地方。标准化测试已经在大量精心选取的人口样本(“常模群体”)中在受控条件下施测。你的分数随后与这个常模群体进行比较,以确定你在分布中的位置。WAIS等临床测试的常模样本由数千名参与者组成,按年龄、性别、教育水平、种族和地理区域分层,以确保样本代表更广泛的人口。这一过程耗资数百万美元,需要数年才能完成。在线测试很少有真正的常模化过程。有些将你的表现与参加过同一在线测试的其他人进行比较——但这是一个自我选择的样本,而非代表性样本。在网上主动寻找IQ测试的人,往往比普通人口受教育程度更高、对认知能力更感兴趣,这使得比较群体产生了偏差。
总结
在线IQ测试可以是有趣且具有一定参考价值的,但不应将其视为智力的准确测量。心理测量学要求受控条件、经过验证的工具和具有代表性的常模样本——这些要求大多数在线测试根本无法满足。
如果你对自己的认知能力感到好奇,在线测试可以作为一个有趣的起点。只需将它产生的数字视为粗略估算,而非最终结论。对于任何重要决定——教育、职业或临床——只有经过正确施测、临床验证的评估才能给你可以依赖的结果。
正如美国心理学会所强调的,智力是复杂的、多方面的,并受到许多因素的影响。没有任何单一数字,无论来自在线测验还是临床测试,都能完全捕捉人类认知能力的丰富性。